Frontend Cache
Frontend Cache
CACHE ‘EM ALL
October 14 2019

Team Lead

Performance problem
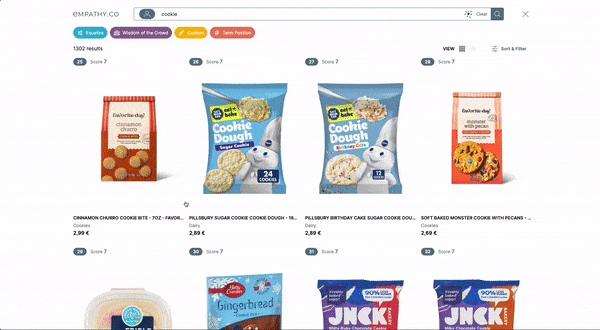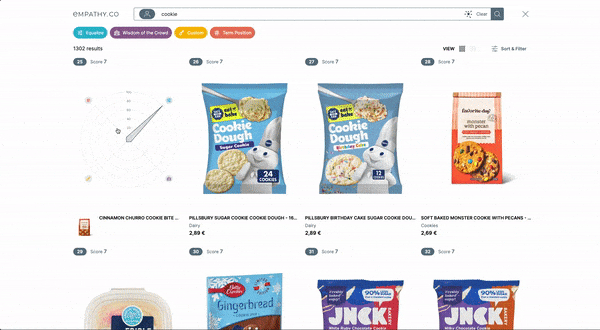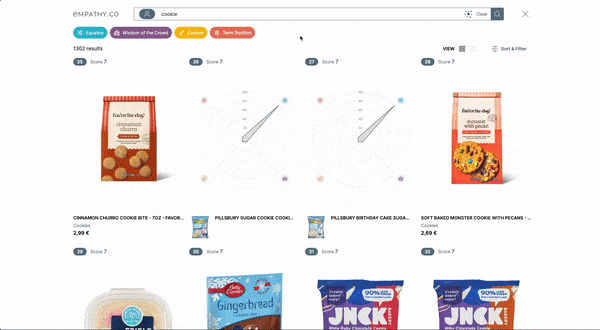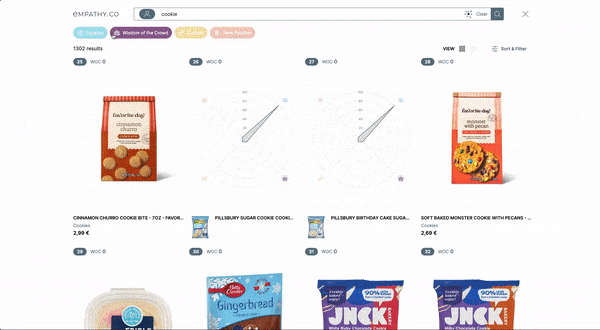
Nowadays, web applications routinely make requests to one or multiple APIs to retrieve and display data. Usually, this data doesn’t change very frequently; it’s the same data that was returned in the previous request.
Think about a search page, for instance: You search for content, receive a list of results, click on a result, and then go back to the list of results.
When you return to the result list, the web app is requesting the same data again, executing transformations to store the same internal data. This is a big task for the browser to repeat, and it also increases workload for the API servers, just to reproduce the same state as before.
Reducing browser and server workload would benefit both the user and the hardware.
Cache idea
What if, as developers, we detect that the user is going to ask for the same query as 15 seconds before, and take this data from a place where we stored it the first time? Naturally, we cannot use the same data forever and, at some point, we will have to refresh it.
We can use the browser localStorage browser to save this data. But what do we use as the localStorage key? The answer: Something that allows us to identify the request. The URL itself is the perfect candidate.
Cache development
Let’s start with a very simple HttpService that makes all the requests to the API; this way, we have a single point that can intercept all the requests. I’m going to use TypeScript as programming language, because it allows us to take advantage of types:
1
2
3
4
5
6
7
export class HttpService {
get<T = any>(url: string, requestOptions: RequestInit): Promise<T> {
return fetch(url, requestOptions)
.then(response => response.json());
}
}
Set and get data with CacheService
Now we are going to create a CacheService class to set and get the data from localStorage:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
export class CacheService {
set(key: string, data: any): void {
const serializedData = JSON.stringify(data);
localStorage.setItem(key, serializedData);
}
get<T = any>(key: string): T | null {
const serializedData = localStorage.getItem(key);
if (serializedData) {
const data: T = JSON.parse(serializedData);
return data;
}
return null;
}
}
Cache usage in HttpClient
The next step is to use this cache in our HttpClient. When this service receives a request, first it checks the cache if it is already stored. If not, then the request is made to the API, and the response is transformed and stored in the cache:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
export class HttpService {
cache = new CacheService();
get<T = any>(url: string, requestOptions: RequestInit): Promise<T> {
const data = this.cache.get<T>(url);
if (data) {
return Promise.resolve(data);
} else {
return fetch(url, requestOptions)
.then(response => response.json())
.then(responseData => {
this.cache.set(url, responseData);
return responseData;
});
}
}
}
When cached search data becomes too old
At this point we are caching every request and not repeating previous requests. But eventually we will need to refresh the data. To achieve that, we are going to add an expiration duration to the saved data and check that parameter before using the data. So let’s modify our CacheService.
We are going to use an Interface to define the data with an expiration duration that will be stored in the localStorage:
1
2
3
4
interface CachedData<T = any> {
expiration?: number;
data: T;
}
Then we add a new parameter ttlInMs to the set method of the CacheService to indicate the duration of the data in the cache for that request. After that, we create an object with expiration field and the data field. This object will be stored in localStorage.
When we retrieve that object in the get method, we check the expiration and, if is expired, we remove the object from localStorage and return null. If not expired, we return the data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
export class CacheService {
set(key: string, data: any, ttlInMs?: number): void {
const cachedData = this.createCachedData(data, ttlInMs);
const serializedData = JSON.stringify(cachedData);
localStorage.setItem(key, serializedData);
}
get<T = any>(key: string): T | null {
const serializedData = localStorage.getItem(key);
if (serializedData) {
const cachedData: CachedData<T> = JSON.parse(serializedData);
if (cachedData.expiration && Date.now() > cachedData.expiration) {
localStorage.removeItem(key);
} else {
return cachedData.data;
}
}
return null;
}
private createCachedData(data: any, ttlInMs: number | undefined): CachedData {
return {
expiration: ttlInMs ? Date.now() + ttlInMs : undefined,
data
};
}
}
Final result
So that’s it. We have created a very simple cache system, to reduce the requests made of the browser and the workload of our backend APIs.
Of course, this was a very simplified approach. In our EmpathyX project, we use a more complex version of this. For example, we clean all the stored requests that are expired and not requested again. Or we extract the localStorage dependency to its own service. In this simple example, the transformation of the response involved just parsing the JSON, but it can be much more complex; in EmpathyX, we transform the API response to our internal Data Model, so we store it after this transformation, which requires more workload to save. Furthermore, we have a way to invalidate the whole cache in case we deploy changes that make the previous cache incompatible.
But the basic idea is the same: Use the localStorage as a cache, in a direct and simple way.
On the horizon: New ways to paginate
We are considering adding more features such as dealing with pagination. In the case of pagination, a new set of results is loaded every time the user scrolls down. For instance, when a user requests a query, the first 24 results are requested and retrieved. Then the user scrolls down and the next 24 results are requested. Now we have two different requests cached, but when the user clicks on a result, visits the result and finally returns to the search results, instead of two requests, only one is done for the first 48 results. This is a new request, distinct from the previous two. This involves managing parameters to know when multiple requests may be joined to match another request. But that rethinking of pagination is for another occasion.